HOW TO EXTRACT TEXT FROM IMAGE USING JAVASCRIPT (OCR with Tesseract.js)?
What is OCR?
OCR (Optical Character Recognition) is the computer process, which helps to recognize printed text or written text characters into searchable and editable data. It involves
- photo scanning of the text character-by-character,
- analysis of the scanned-in image,
- translation of the character image into character codes, such as ASCII, commonly used in data processing.
What is Tesseract.js?
Tesseract.js is a JavaScript based library for OCR, that extracts word from image. Now it is available in many languages. Like English, Spanish, Latin, Chinese etc.
Tesseract.js library is as follow:
<script src='https://cdn.rawgit.com/naptha/tesseract.js/1.0.10/dist/tesseract.js'></script>
Let’s have look at simple example of OCR using tesseract.js.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title> OCR DEMO</title>
</head>
<body>
<img id="userImage" src="test.png"/>
</body>
<script src='https://cdn.rawgit.com/naptha/tesseract.js/1.0.10/dist/tesseract.js'></script>
<script>
var myImage= document.getElementById('userImage');
Tesseract.recognize(myImage).then(function(result){
console.log(result.text);
alert(result.text);
});
</script>
</html>
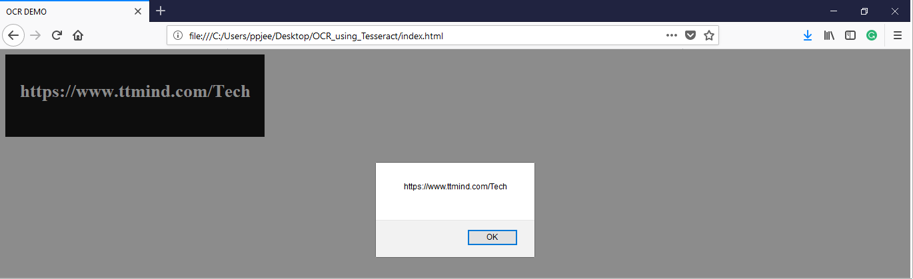
In above example test.png is an image which text are going to extract.

OUTPUT:
For more visit : https://github.com/naptha/tesseract.js
